
After working for more than three years with AWS Lambda and other serverless services, I’ve came across various best practices to improve your way of going serverless. Let me share with you how you can successfully develop your software using serverless functions from a technical perspective.
💡Note: If you are new to serverless functions, I suggest reading my previous blog post about Why Going Serverless. Also, please consider that this is not a blog post about the Serverless framework. It’s rather about serverless functions in general - or Function-as-a-Service (FaaS).
I have collected four best practices below that I think are the most important ones:
- Small Functions: keep your function’s size as small as possible
- Communication: use synchronous or asynchronous communication
- Scalability: scale responsibly!
- Time Management: appropriately use your execution time
However, there are definitely more best practices available. Let me know in the comments which ones are important to you!
Small Functions
The first best practice is the most important one. It’s about keeping a small and limited function scope. The key is to focus on one particular use case following the single responsibility principle. For example, let’s consider your software is receiving webhooks from another service and is processing them. In this case you should create a function which receives the webhook data, makes some validity checks and forwards it to a different (internal) service or serverless function for further processing. In this case you should not include the processing steps into one single function.
There are multiple reasons why you should keep your functions small like this. First, you can later reuse your functions from a different context, e.g. a processing function that can be called from various sources. Second, it makes testing your functions a lot easier if you focus on one task. Third, the performance and scalability of your function improves a lot.
Code Artifact Size
Having a small code artifact is a huge advantage in terms of cold starts. Keep in mind:
The bigger your code’s artifact size, the slower the startup time.
In this context, two questions often come up: (1) Can I use framework/library X in my code? For example, people would like to continue using a framework like Spring (Java) as such frameworks are often used in more traditional architectures. And (2), can I use serverless functions as a REST API? That seems reasonable due to the good support of serverless functions and HTTP events. In terms of the code’s artifact size and the resulting performance problems especially for Java, the general answer is No, you shouldn’t do any of that if it’s not necessary.
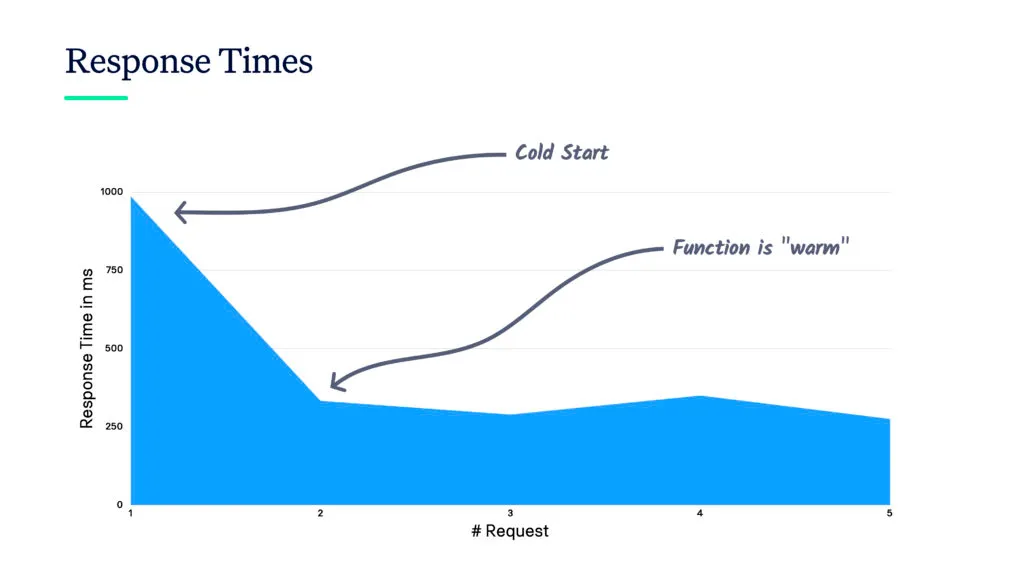
However, there are situations where it’s acceptable to still do it and I’m a big fan of those. Either, it can be reasonable if you do not care too much about the performance. For example, if a serverless function is running in the background. Or if you’re using languages like Python or Node.js which have a really good cold start performance. This is key when using serverless functions as a REST API. I can not recommend Java for this use case.
On the other side, you shouldn’t be too serious about the cold start issue. If your functions get busy more and more (i.e. your software is more popular), they are kept warm for a long time. Thus, you won’t hit the cold start that often. I have seen functions being warm for several hours because they were busy processing data every few seconds.
Communication
The next important best practice is about the communication between serverless functions. There are two ways you can communicate between them: synchronously and asynchronously. I definitely recommend you using asynchronous communication because in many cases it’s the only choice you have but first let’s have a look what it actually means.
Synchronous Communication
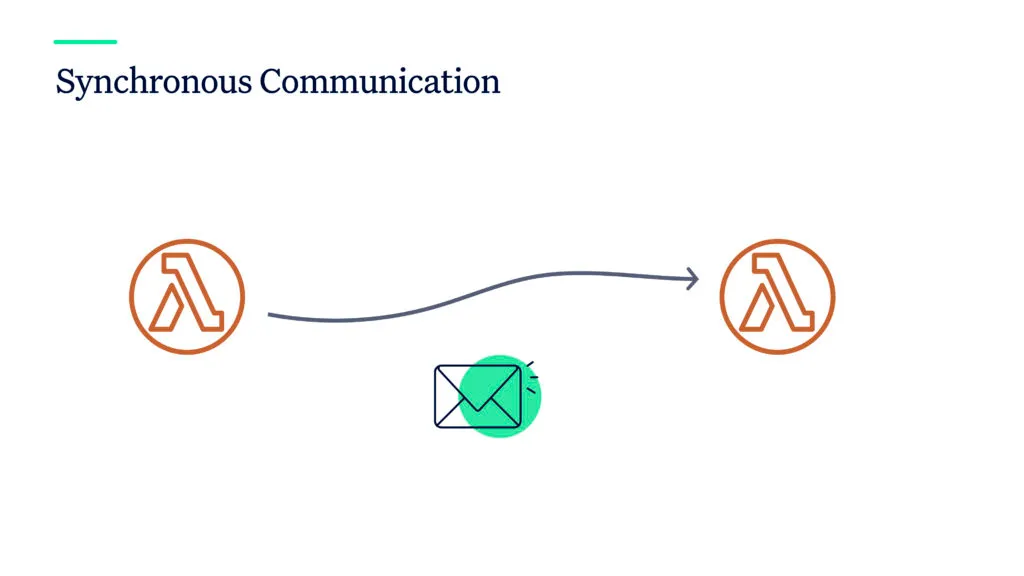
Synchronous communication means directly calling another function by using a cloud provider’s SDK. For AWS Lambda, you can invoke a Lambda function with a payload and wait for it to return. Two problems can occur now: a) the calling function runs out of time while waiting for the other to return; b) the data payload you want to provide is too big and reaching the limits of the service, e.g. 6MB for AWS Lambda.
Both problems can be solved more or less easily. For a), I either suggest increasing the function’s timeout or restructuring your process to make the functions more independent (see asynchronous communication below). For b), you can split a payload and call a function multiple times with each part. Now, the problem might be that your function does not support this scenario because it requires the full payload, not only a part of it.
A better alternative is to use a service like S3 to upload the full payload first, provide a link to the uploaded file in the actual function’s payload and then download the file within the called function. This approach leads to a slightly longer execution time and more costs, but in my opinion it’s the only way of solving the problem.
Asynchronous Communication
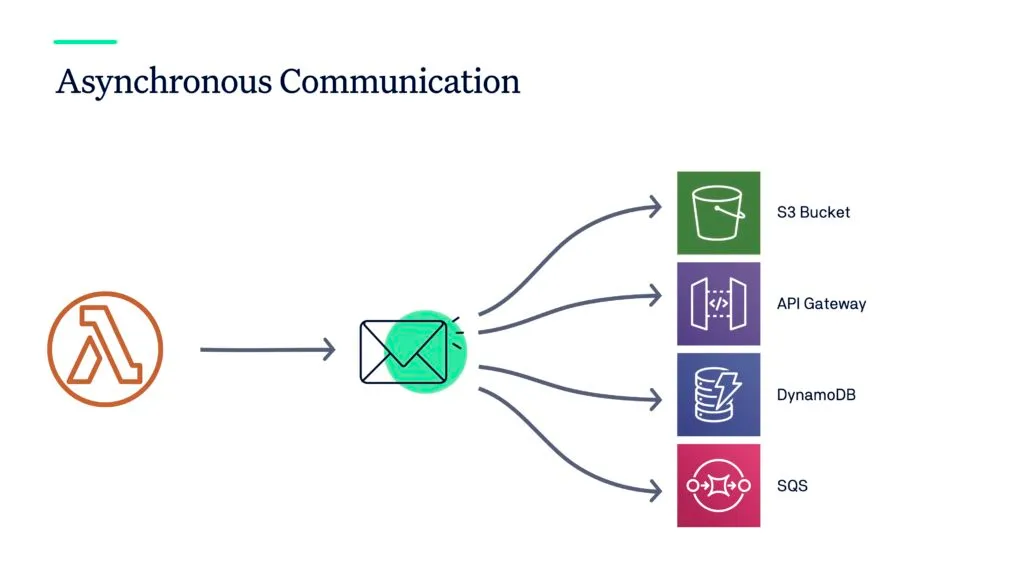
First, push data to a third-party service…
In contrast to synchronous communication, asynchronous communication means calling another function in an indirect way. This involves a separate service in between two or more functions. For example, in an AWS Lambda function you can upload data to S3 which then asynchronously triggers another Lambda function to process this data. Or you can push data into a queuing service where other Lambda functions are consuming it.
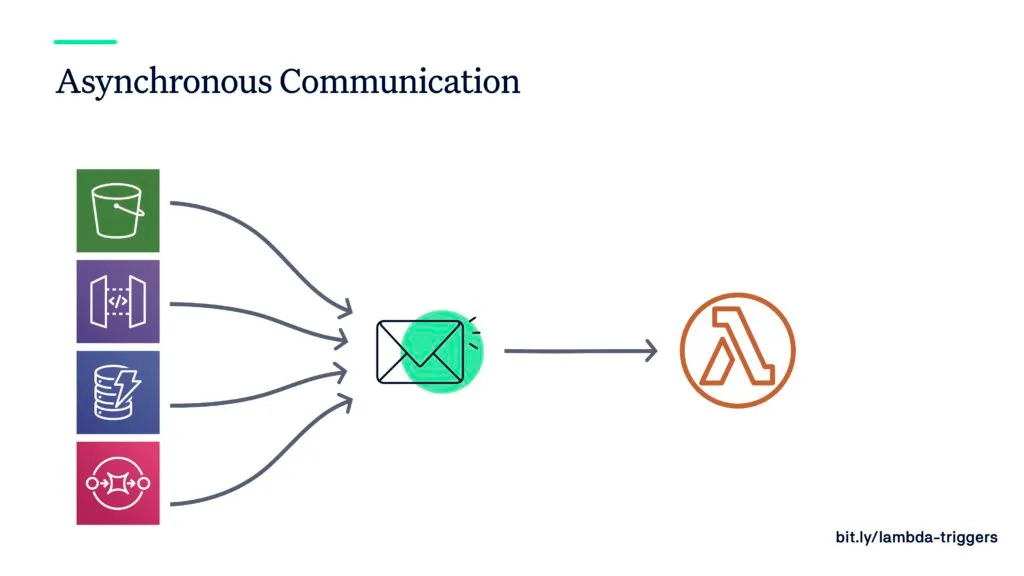
… then let other function(s) be triggered as soon as new data arrives.
Asynchronous communication helps you separating the concerns within your architecture. And it makes your architecture more flexible, because you can easily attach or detach functions to listen to events. Furthermore, you have better control of the data flow and better ways to increase/decrease the performance. As an example, if a lot of data is coming in to a third-party service like S3 and you have more than enough function capacity to consume it, then your performance will be very fast 🚀 That’s often great and in most of the cases desired.
However, by having less capacity of consumer functions, you can decrease the speed of data flow. This is necessary in certain situations. We’ll discuss it in the next section about scalability.
Scalability
A common thought of people new to serverless is:
Serverless functions scale automatically, I don’t have to care about scalability.
This misconception can easily lead to a lot of problems in your software. One major concern is that you do not take care of other services you’re calling. For example, how can you be sure that the API you’re calling at api.example.org can also handle “unlimited scalability” ? Scalability is no free lunch, especially not in older systems. You have to consider this!
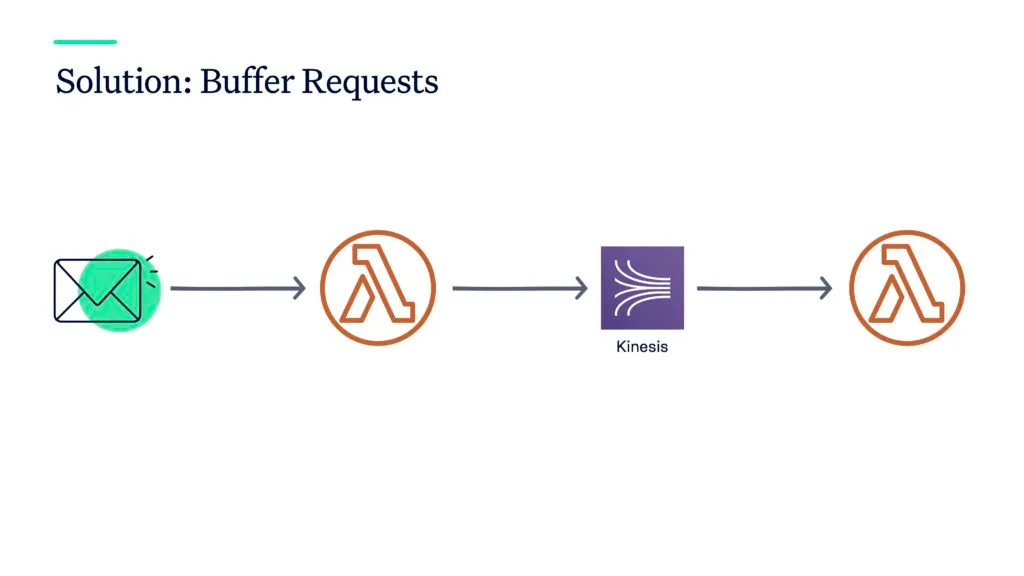
The solution to this problem is to properly limit the executions of your serverless functions. For AWS Lambda, an easy option is to limit concurrent executions to a small number. The option can be applied per function. However, that might not be sufficient as you then have to deal with cases like running out of capacity. Another solution is using a service to buffer any kind of request or execution of your function. This approach is reusing the asynchronous communication best practice from above. You take a service like Kinesis or SQS (instead of S3) where you can (more or less) limit the throughput of your data. Then these services will invoke your functions. For example, in Kinesis you can define how many shards a stream should have. The more shards you have, the more concurrent executions of Lambda functions are necessary.
Time Management
The last important point is about time management. As you know, serverless functions are usually restricted to only run a few minutes (or even seconds for CloudFlare Workers!). Under this term I understand handling the uncertainties of your serverless functions without running into its time limits. Often people think “5 minutes are enough for my function to execute.” But can you really assure your function will never run out of time? Even 5 or 15 minutes can be over quite quickly if you’re processing some data and have to interact with other services. (💡Hint: the previous best practice about small function size will hit you here if you don’t follow it😉) You always need to consider that you’re working in a network, i.e. an unreliable environment. Anything can go wrong! Thus, always use reasonable timeouts when calling other services. Never assume they’ll always respond like in your development tests.
There are a three approaches to solve the timeout problem. The first approach is using recursion. You can see an example using AWS Lambda code in the following picture:

The code is regularly checking the remaining time your function is allowed to run before reaching its timeout. As long as a certain threshold of remaining time is not reached, you continue doing your computation. Otherwise, store your current state somewhere and call “yourself” again. You’ve probably already seen this approach has two big flaws: First, you never know if the same function instance is used when you’re calling yourself. That’s up to the cloud provider to decide it. Secondly, you never know if the chosen threshold is high enough to not run into the timeout. Thus, I can not recommend this approach but it’d be possible.
The second approach is making use of a separate server or container. Here, you outsource all processes where you’re unsure how long it takes to run it. They’ll run on a different service like EC2 or Fargate. You must think now “why do you suggest using EC2 when you’re talking about serverless?” - and you’re probably right 🤷♀️ But you must also admit that long-running tasks aren’t made for serverless functions unless you can split them up into smaller tasks which can run on serverless functions again. And this way of splitting it up often leads to the last approach.
Recommended Approach
The third approach is using Step Functions as the execution engine of your process. Here’s an example of a Step Function state machine using AWS Lambda functions:

This example is very basic but it can be extended to running very complicated processes using loops and decisions. Using Step Functions is a great way of overcoming the timeout constraint if you can split up your tasks into smaller chunks. It’ll take away the work to manage the execution of your functions. For example, it even lets you react on errors within your function, like an exception. For these reasons I believe that Step Functions is a service that is often undervalued but offers great features to complement the serverless experience.
Summary
Serverless is a great “new” way (it’s already more than five years old) of writing software in the cloud. And with other developments, there are even situations where you don’t even need serverless functions anymore. However, if you have read until this point, you realized what to look for when starting your journey to going serverless. And you should have recognized that using other services is a necessity if you want to be successful with serverless functions. At least in most of the cases.
One disadvantage of serverless is that your architecture gets complicated quite quickly. As always in life and especially in the field of software engineering, there is a trade-off you have to make. For serverless functions, the trade-off for a more complicated architecture is almost no maintenance effort and automatic scalability 🚀 You have to decide if you want to pay the price. My recommendations partly cover topics from general recommendations in software engineering like you know from the SOLID principle or others. If you continue applying them, you’ll also succeed in the serverless space 👍
If you want to learn more about serverless, you can have a look at other blog posts here, like Caching in AWS Lambda to improve the speed of your Lambda functions! Or watch one of my previous talks on these topics, like serverless analytics and monitoring.

Related Articles
Migrating a SAM CfnApplication to a CDK NestedStack Without Recreating Resources
How to replace an embedded SAM CfnApplication with a native CDK NestedStack in place, keeping the underlying Lambda and Step Functions resources and their outputs intact.
Serverless and AI on AWS in 2026: Governing Agents and the New Agent Economy
Part two of the 2026 serverless AI tour: Bedrock AgentCore for production governance, Strands Agents, the AWS Serverless agent plugin, and WAF's new AI traffic monetization.

Serverless and AI on AWS in 2026: Lambda Gets Hands, S3 Gets Memory
A practitioner's tour of how AWS rebuilt serverless compute and storage for AI agents in 2026: Lambda MicroVMs, Durable Functions, S3 Vectors, S3 Annotations, and managed RAG.
Build, Test and Debug AWS Lambda Container Images Locally with Docker
Run AWS Lambda container images on your machine with the Runtime Interface Emulator. Build the image, pass IAM or AWS SSO credentials, verify them with STS, and shell into the container to debug.