
In every software application, there are usually two main reasons to cache data: a) to improve performance and b) to reduce costs. Caching in AWS Lambda is not different. Instead, the reasons for caching might be even more important in this context. This blog post explains why it could be necessary for you and shows how to implement different caching options. In other words: How to find the best AWS Lambda cache option! This blog post is based on a talk I gave at the AWS User Group Stuttgart meetup in December 2018. You can find the slides here and the code is provided in this GitHub repo.
Reasons for Caching
Let’s talk about the reasons first, why you need caching in AWS Lambda. Often a Lambda function will not only do some internal/local processing. It also calls other systems or services. This could be a database like DynamoDB or any kind of service with an API. Such calls might be costly, e.g. in terms of time to wait for a response or actual money if the pricing is based on number of API requests. Since you pay for the execution time of a Lambda function as well, waiting for a response will also cost you money in the end. You can easily save some time (and money 😉) if you don’t have to wait for expensive API calls in each execution and instead cache certain data. Furthermore, the cost reason is even more dramatic if you think about the scalability of a function. Just imagine the following scenario:
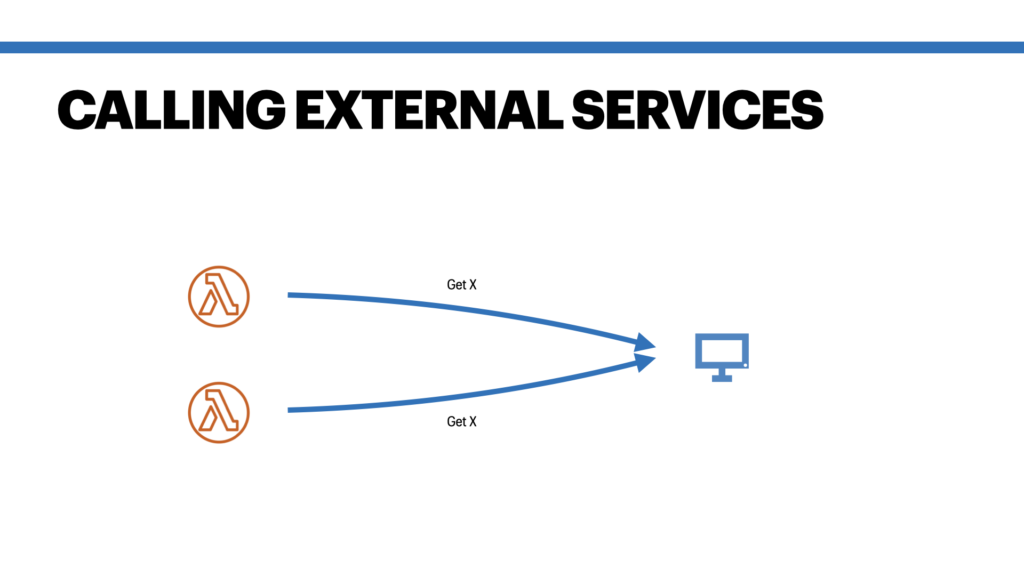
You need to understand two things here:
- Your Lambda function will make the same request for each invocation of the same function’s instance.
- Each instance of your Lambda function will make the same request as well.
In many use cases it’s not necessary to make expensive calls again and again. Hence you can save a lot by simply caching your data for a certain amount of time. Before we look at the different caching options, we quickly need to investigate how the code of a Lambda function is executed. With this knowledge, we can then introduce caching into our functions.
Execution Process of a Lambda Function
Each Lambda function is experiencing the same execution process: if no instance of your Lambda function is available or all existing instances are busy with invocations, a new instance is started (a “cold start“). This cold start involves an initial start of the Lambda runtime (e.g. a Node runtime or a JVM in Java). This includes some initialization code which e.g. is declared before your Lambda function handler. In NodeJS this could be requiring a certain dependency or read an environment variable. In Java it might be importing classes and doing some field initializations in your constructor. After this initialization phase the actual function handler is called. Here is a NodeJS example from my slides explaining this:
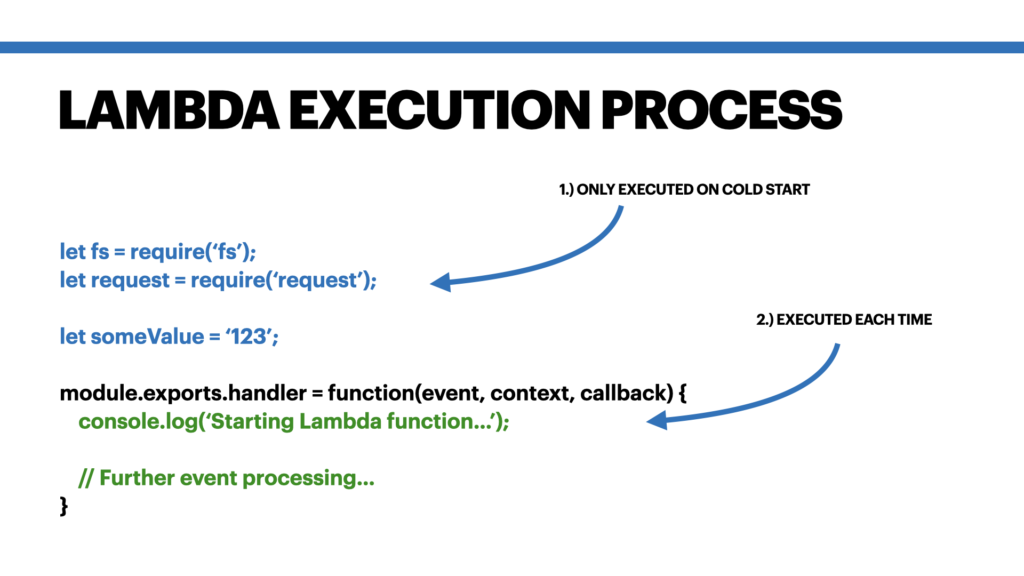
One advantage is that the variables outside of the handler function will survive the Lambda invocations. That means you can set a value in one invocation and it will be accessible within all following invocations. This works for one Lambda instance until that specific Lambda instance is shutdown. The caching “trick” is now that you make use of these variables outside of your handler function scope. This is described in more detail below.
Caching Options
Now, in order to cache your data, you have three options available:
- simple caching by using simple variables declared outside of a Lambda handler function,
- DynamoDB caching by using DynamoDB as our cache,
- custom caching by using a caching library on separate servers or
- managed caching by using a managed caching service.
Simple Caching
With a simple caching approach, you declare a variable outside of a Lambda handler function which stores your cached data. In Node.js, this could be a simple key value object. In Java, you can use a HashMap or other Map implementations. For example, you can store “userkey_123” as key and “John Smith” as value. The general process will look like this: In the first call of your Lambda function, you’ll check if you have a key “userkey_123” stored in your local cache variable. If yes, you’ll use it and continue in your code. If not, you’ll make a call to your external service and store the response in your local cache. It’s pretty easy, hence simple caching. Here is an example written in Node.js:
let cachedValue;
module.exports.handler = function(event, context, callback) {
console.log('Starting Lambda.');
if (!cachedValue) {
console.log('Setting cachedValue now...');
cachedValue = 'Foobar';
} else {
console.log('Cached value is already set: ', cachedValue);
}
};
You can extend the code to also expire the cache contents after some time. Popular libraries are node-cache for Node.js or the Cache class from Guava library for Java.
However, there are two things you need to consider: First, make sure that you correctly scope your cached data. That means, take care that your Lambda function might also be called in different contexts. For example, if your function can be invoked with different parameters, e.g. with different user objects, make sure you don’t accidentally leak data to a different context. In such a case you can scope a key to prevent that, for example by using cache[userkey] or some other identifier. Second, please consider that this cache is only accessible for one particular Lambda function instance. If your Lambda function is experiencing a lot of traffic and multiple instances have been started, then each Lambda function has its own local cache. These local caches are not synchronized! However, using such a local cache still helps you avoiding the same expensive calls within the same instance 😊 If you need to synchronize cached data between the instances, you should consider using one of the following caching options.
[mailjet_subscribe widget_id=”3″]
DynamoDB Caching
In a traditional caching setup, you’d use a system like Redis or Memcached to cache your data. This is also discussed below in the Custom Caching and Managed Caching sections. However, since DynamoDB has such great response times of low double digits within the AWS network (in my experience also often below 10ms), it’s a great alternative to use DynamoDB as our caching service. This means, instead of using a local variable outside of your handler function, you just make a quick call to your DynamoDB cache table and retrieve the cached data from there. So the process looks like this:
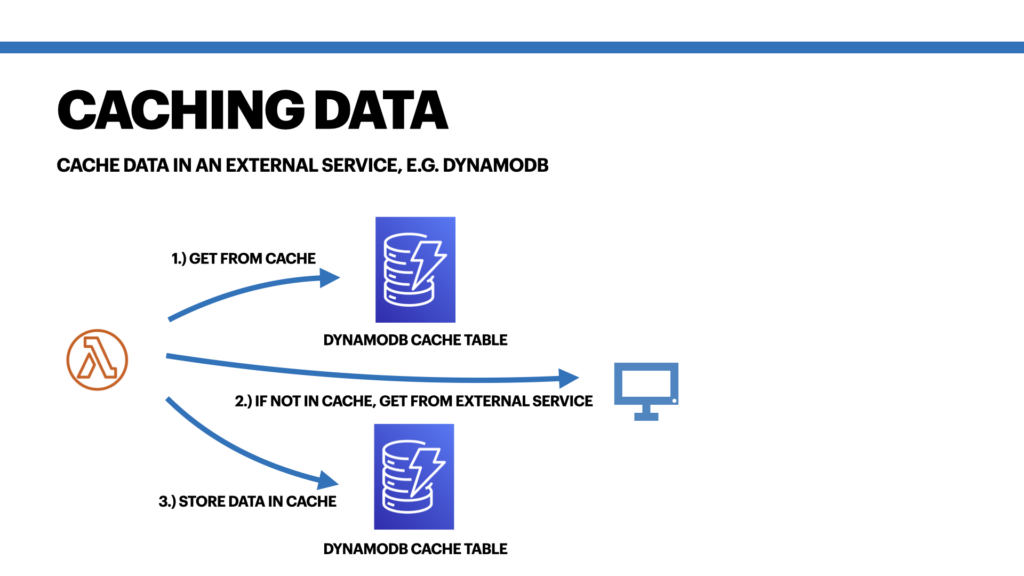
- Check if your DynamoDB cache table contains an entry for a specific key.
- If yes, continue with the cached value.
- If no, make a call to your external service and store your data in your cache table.
This has the big advantage that all of your Lambda functions can benefit from the cache. It’s like simple caching on steroids because the cache is kind of synchronized between all Lambda functions. You can further improve this setup by using DynamoDB Accelerator (DAX) to reduce the response times even more. (Consider that DAX might introduce new challenges 😉 )
Custom Caching
In a custom caching approach, you make use of an existing caching library/system (e.g. Hazelcast, Redis or Memcached). You can use such a library and host it on your machines, e.g. on EC2 instances. This can be useful if you already have EC2 instances in your stack and want to add some more to provide you with a cache cluster. After setting up your cache, you simply add some code to your Lambda functions and connect to your own cache. With this approach, you keep the same access workflow as before: check if the cache contains your key => if not, make your expensive request once and then add the key value pair to the cache. This usually works fine as long as you let your Lambda functions only connect as a client and not as a full cluster node. A full cluster node like in Hazelcast would first synchronize a big chunk of data, because it’s part of the cluster. For a Lambda function, this won’t be acceptable.
Moving to a VPC
Although the custom caching might sound like a good solution to you, you need to be aware of a catch here: by default, EC2 instances are placed into a default (public) VPC in your AWS account. This also means, they will be open to the public and potentially everyone could access your cache. You probably want to avoid that. Hence you should use a custom VPC (and a private subnet) where you can put your EC2 cache instances into.
However, a second problem arises with this move. By default, a Lambda function is also placed into a default (public) VPC. The problem is, by default you cannot access any resource inside a custom VPC from within your Lambda function. Hence, you also have to move your Lambda functions into the same VPC as your EC2 instance where your cache is running on. Unfortunately, this might increase the startup time of your Lambda functions. The reason is that AWS has to dynamically create an Elastic Network Interface (ENI) and attach it to your Lambda function instance. With an ENI your Lambda function can access the resources. (Update: AWS has improved this situation a lot, so the disadvantage isn’t that big anymore)
The CloudFormation template in my repository shows you how to setup such an infrastructure. I’m using a VPC with a public subnet, a subnet for my Lambda functions and a subnet for the EC2 cache instances. The Lambda functions have access to the cache instances in the cache subnet. They can also communicate to the internet by leveraging a NAT Gateway which sits in the public subnet.
Managed Caching
In a managed caching approach, the setup compared to the custom caching approach is pretty similar. The big difference is that you will use a managed caching service instead of provisioning your own caching instances. For example, you can use AWS ElastiCache which is based on Redis or Memcached. Both are widely supported caching systems with SDKs for a lot of languages. As said, the setup is similar: you’ll have to place the ElastiCache cluster into a VPC and move your Lambda functions into the VPC as well. In contrast to the previous approach there are certain advantages using a managed service: a quick setup is possible, no maintenance work is necessary on your side and there is a good compatibility of Redis and Memcached. Especially the maintenance aspect might be worth to consider! The disadvantages are the same like for the custom caching: your Lambda functions take longer to start, because the ENI needs to be created dynamically.
Conclusion
After discussing all options for caching in AWS Lambda, it’s time to give a quick conclusion. In my opinion you should prefer the simple caching solution wherever possible. One use case might be that you retrieve data from an API which does not change quite often, e.g. some settings. This is easy to cache but saves you a lot of time. If you want to optimize this, use a DynamoDB table instead – this works pretty well for most of the use cases. If you really need some advanced caching mechanism, then you should use a custom or managed caching solution. The startup time of your function will take longer, but AWS will also bring some updates in 2019 made some updates to improve that. I recommend watching a bit of the video A Serverless Journey: AWS Lambda under the hood.