Remove old CloudWatch log groups of Lambda functions
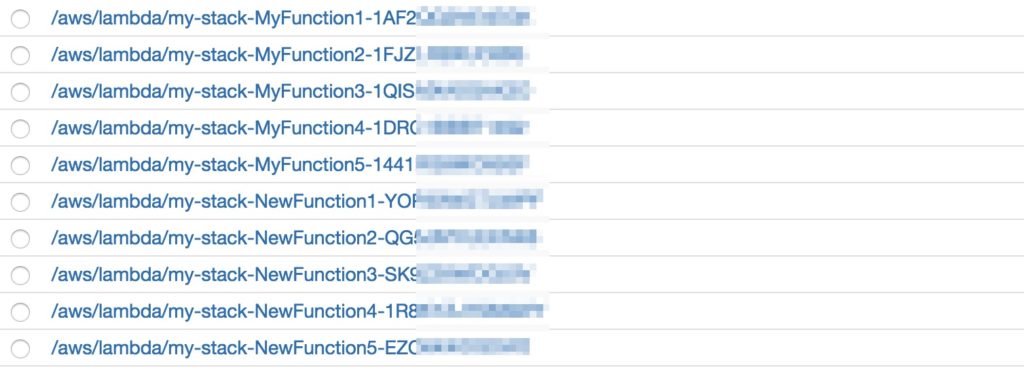
Do you recognize this view when looking into your CloudWatch log groups? Each AWS Lambda function has an associated CloudWatch log group. However, there is no cleanup process available as soon as a relationship between a CloudWatch log group and Lambda function expires. In that case it’s necessary to remove these old log groups manually. […]
Remove old CloudWatch log groups of Lambda functions Read More »


